
Multiple Object Tracking (MOT) represents one of the most challenging and practically significant problems in computer vision, involving the simultaneous detection and tracking of multiple objects across video sequences while maintaining consistent identity assignments throughout their trajectories. Unlike single object tracking, which focuses on following one target, MOT must handle complex scenarios where numerous objects interact, occlude each other, and exhibit varying motion patterns within the same scene.

The importance of MOT extends far beyond academic research, serving as a cornerstone technology for autonomous driving systems that must track pedestrians and vehicles in real-time, surveillance networks monitoring crowded environments, robotics applications requiring multi-agent coordination, and sports analytics platforms analyzing player movements. These applications demand not only high accuracy but also real-time performance, making MOT a critical bridge between theoretical computer vision advances and practical deployment.
The evolution from single to multi-object tracking has introduced unique challenges that distinguish MOT as a complex optimization problem. Objects frequently undergo partial or complete occlusion, leading to identity switches where tracking algorithms incorrectly reassign object IDs. Similar appearances between objects, particularly in crowded scenes with uniform clothing or identical vehicles, further complicate the association process. Additionally, varying motion patterns, from linear pedestrian movement to erratic sports player trajectories, require robust prediction models.
Fundamentals of Multiple Object Tracking
Understanding the fundamentals of Multiple Object Tracking requires diving into the intricate machinery that powers modern tracking systems. At its core, MOT operates as a sophisticated orchestration of four essential components, each playing a critical role in transforming raw video data into meaningful object trajectories.
Let us look at some core components and methodology:
Target Initialization and Object Definition
The journey of any tracking system begins with target initialization – the crucial decision of what to track and how to define it. This foundational step determines the entire tracking pipeline's success. Modern systems employ two primary approaches: manual initialization, where human operators define regions of interest through bounding box annotations, and automatic initialization, which leverages machine learning to identify trackable objects without human intervention.
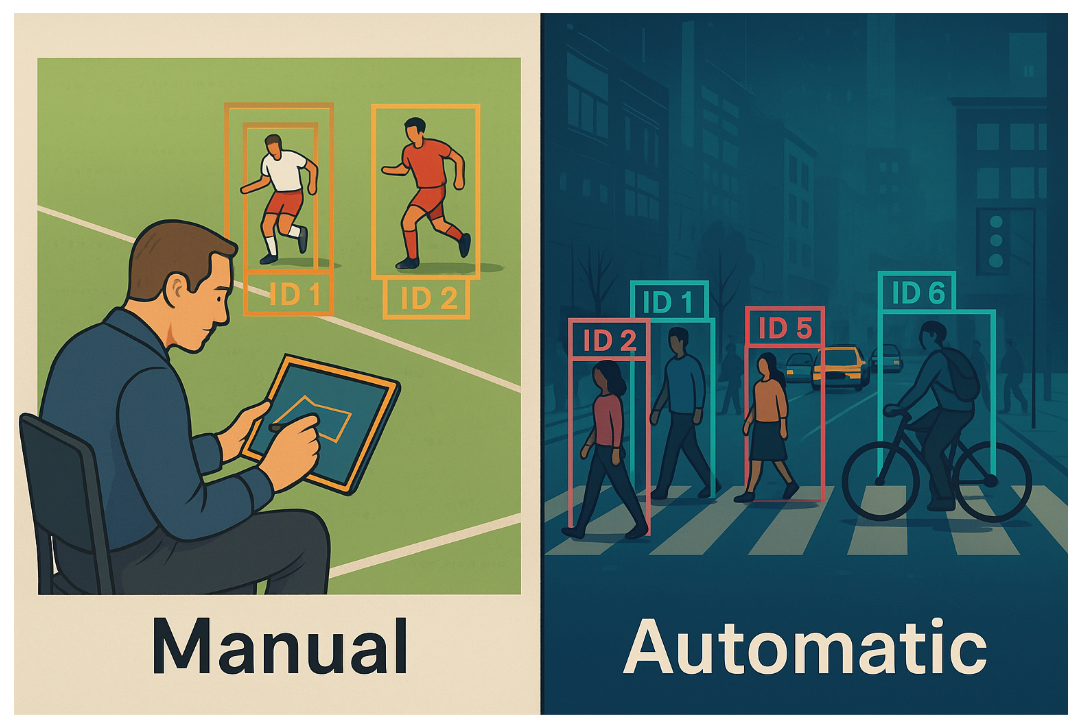
Manual approaches offer precision and control, particularly valuable in specialized applications like sports analytics where specific players must be tracked. However, automatic initialization has become the dominant paradigm, enabling scalable deployment across diverse scenarios from surveillance systems monitoring hundreds of pedestrians to autonomous vehicles detecting dynamic road participants.
Appearance Modeling for Visual Consistency
Once targets are defined, the system must learn to recognize them consistently across frames despite lighting changes, pose variations, and partial occlusions. This challenge is addressed through sophisticated appearance modeling techniques that create robust visual representations using feature descriptors.
Modern systems employ deep learning-based descriptors that capture both low-level visual features (color, texture, edges) and high-level semantic information. These descriptors are then integrated into statistical models that can identify objects under varying conditions, accounting for natural appearance variations while maintaining discriminative power to distinguish between similar-looking targets.
Motion Estimation and Prediction
The temporal nature of video sequences provides powerful cues for tracking through motion estimation and prediction. This component employs mathematical frameworks like Kalman filters for linear motion scenarios, particle filters for non-linear trajectories, and linear regression techniques for trend analysis.
The magic lies in dynamic state estimation – predicting where objects will appear in future frames based on their motion history. This predictive capability is essential for handling temporary occlusions and maintaining tracking continuity when objects briefly disappear from view.
Target Positioning and Association
The final core component tackles the association problem – determining which detections in the current frame correspond to which tracked objects from previous frames. This seemingly simple task becomes computationally complex in crowded scenes with multiple similar objects.
Systems employ various strategies, from greedy search algorithms that make locally optimal decisions to maximum posterior estimation methods that consider global optimization. The choice of association method significantly impacts both tracking accuracy and computational efficiency.
Two-Stage MOT Framework
Modern MOT systems typically follow a two-stage framework that separates detection from tracking, enabling modular design and optimization. This modular approach has dominated the field due to its intuitive design, computational efficiency, and ability to leverage advances in object detection independently from association algorithms, enabling researchers to optimize each component separately while maintaining system-wide performance.
Stage 1: Object Detection
The first stage focuses on identifying objects in individual frames without temporal considerations. This stage integrates seamlessly with state-of-the-art detectors like YOLO and Faster R-CNN, leveraging their sophisticated architectures for accurate object localization.
Real-time applications demand careful balance between detection accuracy and computational efficiency. Systems must process frames fast enough to maintain temporal coherence while providing sufficiently accurate detections for reliable tracking.
Stage 2: Instance Association
The second stage transforms independent detections into coherent trajectories through temporal information integration. This stage maintains consistent ID assignments throughout video sequences, ensuring that each tracked object retains its identity despite appearance changes, occlusions, or complex motion patterns.
This framework's elegance lies in its modularity – detection and association components can be independently optimized and upgraded, enabling rapid adaptation to new scenarios and technological advances.
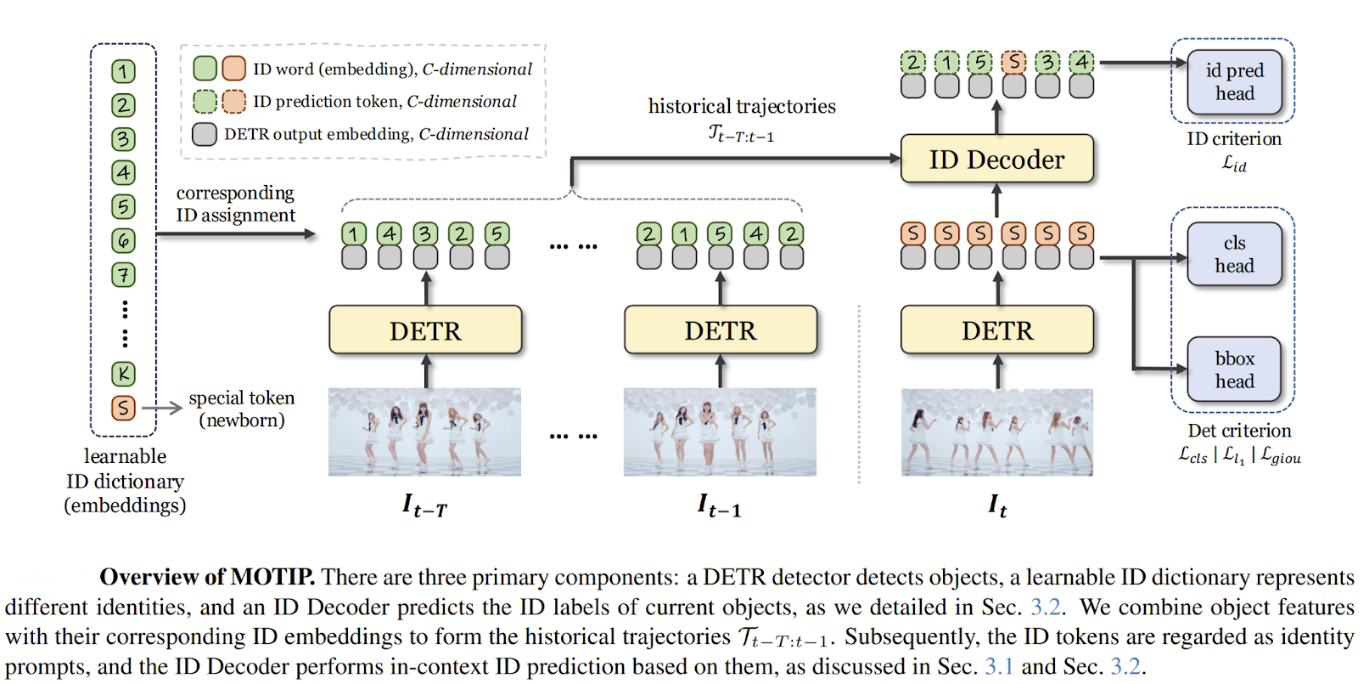
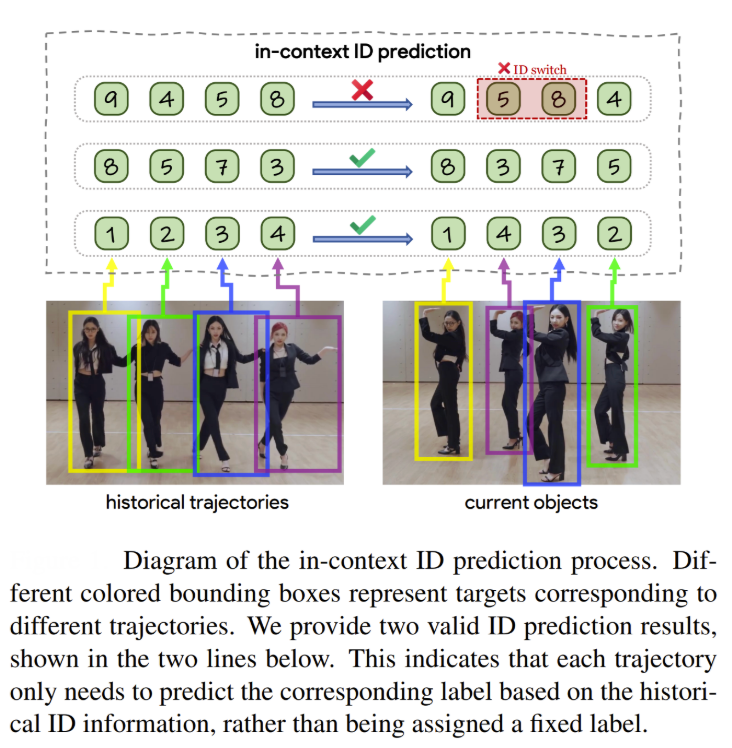
For example, MOTIP represents one of the most recent approaches (CVPR 2025) to the two-stage MOT framework that transforms traditional object association into an end-to-end trainable process. Unlike conventional methods that rely on handcrafted heuristics for the association stage, MOTIP treats the second stage as an "in-context ID prediction" problem, where objects are assigned consistent identity labels based on historical trajectory information rather than fixed global classifications.
The method employs Deformable DETR as its detector in the first stage, followed by a transformer-based ID Decoder that predicts identity labels using a learnable ID dictionary containing K+1 embeddings (K regular identities plus one special token for newborn objects). This innovative formulation allows the model to handle unseen trajectories during inference by maintaining label consistency within trajectories rather than requiring specific semantic labels, effectively solving the generalization problem that plagued previous ReID-based approaches.
MOTIP achieved state-of-the-art results across multiple challenging benchmarks demonstrating that the two-stage paradigm can be significantly enhanced through learnable association mechanisms while maintaining its fundamental modularity and computational efficiency.
Genres of MOT Approaches
The landscape of MOT has evolved into several distinct methodological paradigms, each addressing the fundamental challenge of maintaining object identities across video sequences through different computational strategies. Let us look into the most promising of these methods.
Tracking-by-Detection Methods
Tracking-by-detection methods represent the foundational and most widely adopted paradigm in multiple object tracking, operating on the principle of decomposing the complex MOT problem into two sequential stages: object detection in individual frames followed by temporal association across frames like we discussed in the previous section.
Joint Detection and Embedding Approaches
Joint detection and embedding methods represent a sophisticated evolution in MOT by simultaneously performing object detection and feature extraction within unified architectures. These approaches optimize both tasks end-to-end, enabling the detection network to learn features specifically tailored for tracking applications rather than generic object recognition.
For example, YOLO11-JDE represents an innovative joint detection and embedding approach that seamlessly integrates real-time object detection with self-supervised Re-Identification (Re-ID) within the tracking-by-detection framework. The method enhances the YOLO11 architecture by incorporating a dedicated Re-ID branch that simultaneously learns discriminative appearance features during the detection process, eliminating the computational overhead of separate feature extraction stages.

What sets YOLO11-JDE apart is its self-supervised training paradigm that removes the dependency on costly identity-labeled datasets, instead employing triplet loss with hard positive and semi-hard negative mining strategies to learn robust embeddings directly from detection data. The system maintains the classical two-stage MOT structure: the unified YOLO11 network first detects objects while extracting appearance features in a single forward pass, followed by a sophisticated association stage that integrates motion prediction, appearance similarity, and spatial location cues for robust tracking.

This joint optimization approach achieves remarkable efficiency gains, delivering competitive performance on MOT17 and MOT20 benchmarks while operating at higher frame rates and using up to ten times fewer parameters than existing JDE methods, making it particularly attractive for real-world deployment scenarios where computational resources are constrained.
Heuristic-Based Methods
Heuristic-based tracking methods employ carefully crafted rule-based association strategies that leverage domain knowledge and empirical observations about object behavior. These approaches excel in scenarios with predictable motion patterns and have proven particularly effective in densely populated datasets where objects follow relatively linear trajectories.
TrackTrack represents a novel heuristic-based approach that challenges the conventional global optimization paradigm in multi-object tracking by introducing two key track-focused strategies: Track-Perspective-Based Association (TPA) and Track-Aware Initialization (TAI).

Unlike traditional methods that apply the Hungarian algorithm for global cost minimization, TrackTrack employs a track-perspective heuristic that prioritizes local matching precision by ensuring each track is associated with the most suitable detection result through iterative minimum distance selection. The TPA strategy comprehensively utilizes all available detection candidates—including high-confidence detections, low-confidence detections, and even high-confidence detections discarded during NMS (non-maximal suppression)—through a single joint association stage rather than multi-stage cascades.

This approach addresses the fundamental limitation of conventional methods that treat tracks and detections as independent sets, when in reality they represent interdependent objects with correct assignment answers. The TAI component prevents spurious track generation by leveraging active track information to suppress initialization of detection results that heavily overlap with existing tracks, using a track-aware NMS process with undeletable anchors positioned at matched track locations. TrackTrack demonstrated that well-designed heuristic strategies can outperform complex global optimization approaches while maintaining computational efficiency at over 160 FPS.
Motion-Based Tracking
Motion-based tracking methods form the backbone of real-time MOT systems by leveraging object motion patterns for association through IoU matching and motion prediction algorithms.
The SORT (Simple Online and Realtime Tracking) algorithm pioneered this approach using Kalman filters for motion prediction combined with Hungarian algorithm optimization for assignment, achieving remarkable efficiency through its four-component architecture: detection, estimation, data association, and track identity management.
ByteTrack revolutionized motion-based tracking by introducing a two-stage association process that recovers low-confidence detections typically discarded by traditional methods. The algorithm first matches high-confidence detections with existing tracks, then performs a second association phase using low-confidence detections to recover occluded or partially visible objects. This simple yet effective approach demonstrates that considering all detection boxes, rather than only high-scoring ones, can significantly improve tracking robustness in challenging scenarios.

Offline Tracking Methods
Offline tracking methods leverage global optimization approaches and batch processing capabilities to achieve superior accuracy by considering entire video sequences simultaneously rather than making frame-by-frame decisions.
BiTrack demonstrates the power of offline processing through its bidirectional trajectory re-optimization framework, which includes 2D-3D detection fusion, initial trajectory generation, and bidirectional trajectory refinement. The method employs point-level object registration with density-based similarity metrics for accurate detection fusion, vertex-based similarity metrics for data association, and sophisticated track management including false alarm rejection and track recovery mechanisms.

The bidirectional optimization scheme reorganizes track fragments of different fidelities using greedy algorithms while refining trajectories through completion and smoothing techniques, achieving state-of-the-art performance on KITTI datasets by leveraging the temporal context unavailable to online methods.

End-to-End Tracking Approaches
The emergence of end-to-end tracking approaches represents a paradigm shift from traditional tracking-by-detection methods, leveraging transformer architectures to perform detection and association simultaneously within unified frameworks. These methods eliminate the need for explicit post-processing steps and heuristic association rules, instead learning temporal relationships directly from data through sophisticated attention mechanisms.
Transformer-Based Architectures
Transformer-based architectures have revolutionized the end-to-end tracking paradigm by introducing sophisticated neural network frameworks that can simultaneously model object detection, feature extraction, and temporal association within unified systems. These architectures leverage the power of query-based object representation and learnable embeddings to capture complex temporal dependencies across video sequences, eliminating the need for handcrafted association rules while enabling the model to learn optimal tracking strategies directly from data through end-to-end optimization.
Let us look at some of the most revolutionary architectures that shaped the field of MOT.
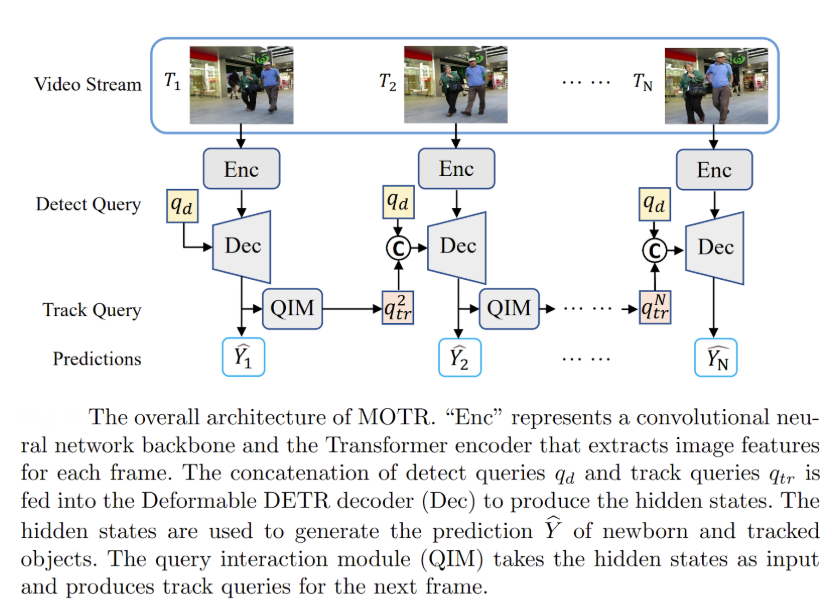
MOTR
MOTR (Multiple Object Tracking with Transformer) pioneered the end-to-end tracking paradigm by extending DETR and introducing the revolutionary concept of "track queries" to model tracked instances throughout entire video sequences.

Unlike traditional methods that perform detection and association as separate stages, MOTR formulates MOT as a set-of-sequences prediction problem where track queries are transferred and updated frame-by-frame to perform iterative predictions seamlessly. The method employs tracklet-aware label assignment for one-to-one matching between track queries and object tracks, complemented by a temporal aggregation network and collective average loss to enhance long-range temporal relation modeling.

FastTrackTr
FastTrackTr addresses the computational efficiency challenges inherent in transformer-based MOT by introducing a novel cross-decoder mechanism that implicitly integrates historical trajectory information without requiring additional queries or decoders.

FastTrackTr's single decoder design enables genuine end-to-end tracking by passing queries from one frame to the next, where these queries predominantly contain image features enhanced with temporal information. The training-friendly design allows for larger batch sizes due to easier mask generation, making it considerably more practical for deployment compared to recent transformer-based MOT methods that require extensive computational resources and complex training procedures. This approach successfully bridges the gap between accuracy and efficiency in end-to-end MOT, demonstrating that transformer architectures can achieve real-time performance without sacrificing the sophisticated temporal modeling capabilities that make end-to-end approaches attractive for complex tracking scenarios.

Co-MOT
Co-MOT represents an end-to-end tracking approach that addresses the fundamental training imbalance problem that hinder transformer-based MOT methods through its innovative “COopetition Label Assignment” (COLA) strategy and shadow query concept.

Unlike traditional end-to-end methods such as MOTR that suffer from poor detection performance (as shown in the image above) due to exclusive assignment of tracked objects to tracking queries and newborns to detection queries, Co-MOT introduces a coopetition paradigm where tracked objects are also assigned to detection queries in intermediate decoders, enabling detection queries to enhance tracking query representations through self-attention mechanisms.

The method further addresses the one-to-one bipartite matching limitation by implementing a "shadow set" approach where each query is augmented with multiple shadow counterparts initialized with limited disturbance, creating a one-to-set matching strategy that provides more positive training samples and improves generalization ability. During training, the most challenging query in each shadow set is selected using maximum cost criteria for discriminative representation learning, while inference employs confidence-based representative selection to maintain tracking continuity.
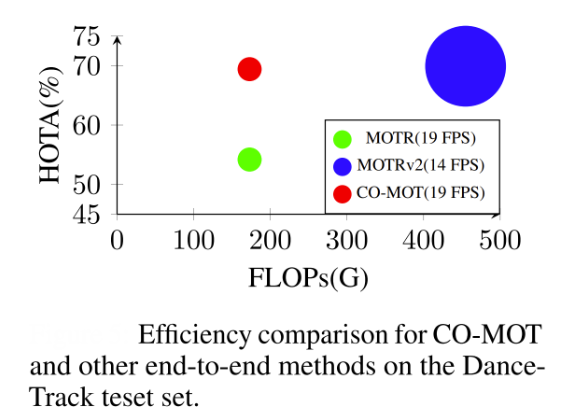
Co-MOT achieved remarkable performance improvements, delivering 69.4% HOTA on DanceTrack while requiring only 38% of MOTRv2's computational cost and achieving 1.4× faster inference speed, effectively bridging the gap between end-to-end and tracking-by-detection paradigms without requiring additional pre-trained detectors.
Attention Mechanisms for Object Relationships
The power of transformer-based MOT lies in sophisticated attention mechanisms that model complex object relationships across temporal sequences. These mechanisms enable models to dynamically focus on relevant parts of input sequences by computing attention weights that reflect the relative importance of each element. In MOT applications, attention mechanisms facilitate the modeling of object interactions, occlusion relationships, and temporal dependencies that would be challenging to capture through traditional heuristic approaches. The query-key-value framework allows track queries to attend to relevant spatial and temporal features, enabling robust object association even in complex scenarios with similar appearances and non-linear motion patterns.
Cross-View and Multi-Frame Attention Mechanisms
Recent advances in transformer-based MOT have introduced sophisticated attention mechanisms that extend beyond traditional single-frame processing. ViewFormer demonstrates the power of spatiotemporal modeling through its innovative view attention mechanism combined with multi-frame streaming temporal attention.
This approach enables the model to simultaneously process multiple viewpoints while maintaining temporal consistency across frames, addressing the fundamental challenge of 3D object tracking in multi-camera scenarios. The view attention mechanism allows the model to selectively focus on the most informative camera views for each tracked object, while the temporal attention component ensures smooth trajectory estimation across time.
Temporal Query Denoising for Enhanced Association
TQD-Track introduces a novel approach to attention-based MOT through its Temporal Query Denoising (TQD) mechanism. Unlike traditional query denoising that operates within single frames, TQD enables denoising queries to carry temporal information and instance-specific feature representations across multiple frames.
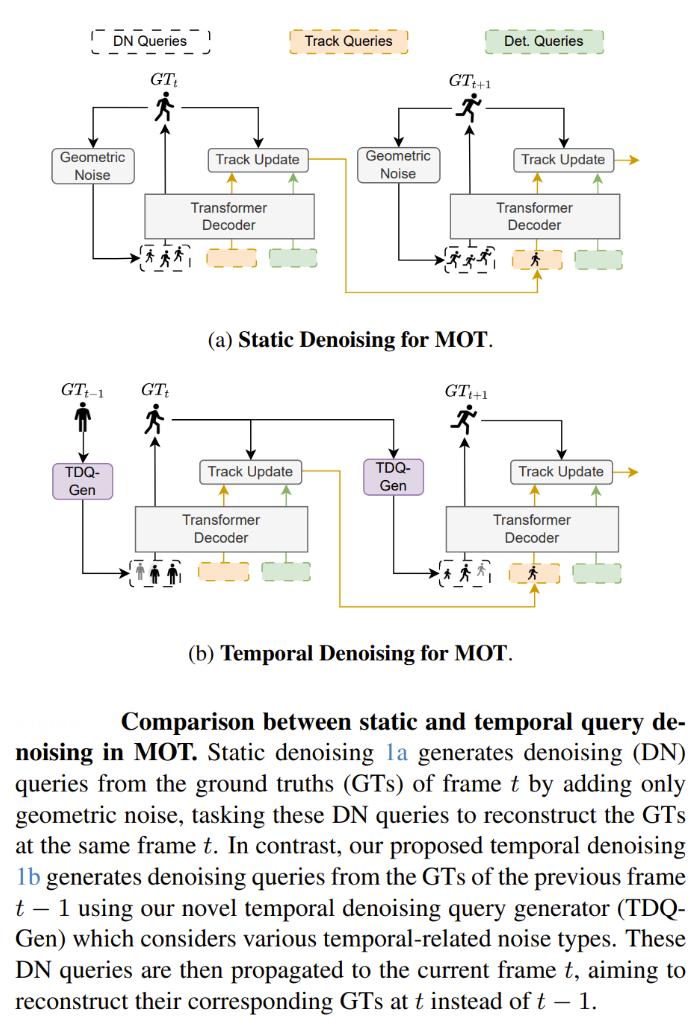
This temporal awareness allows the attention mechanism to better model object relationships over time by simulating real-world challenges such as occlusion, appearance changes, and motion blur through diverse noise injection strategies.

TQD-Track demonstrates that attention mechanisms benefit significantly from temporal context, with paradigms incorporating explicit learned data association modules showing the largest performance improvements.
Cross-Attention for Object Interaction Modeling
The SMOTer framework exemplifies sophisticated attention-based object relationship modeling through its cross-attention mechanisms for interaction recognition. The system employs cross-attention to fuse features between active and passive trajectories, enabling the model to understand complex object interactions that go beyond simple spatial proximity.
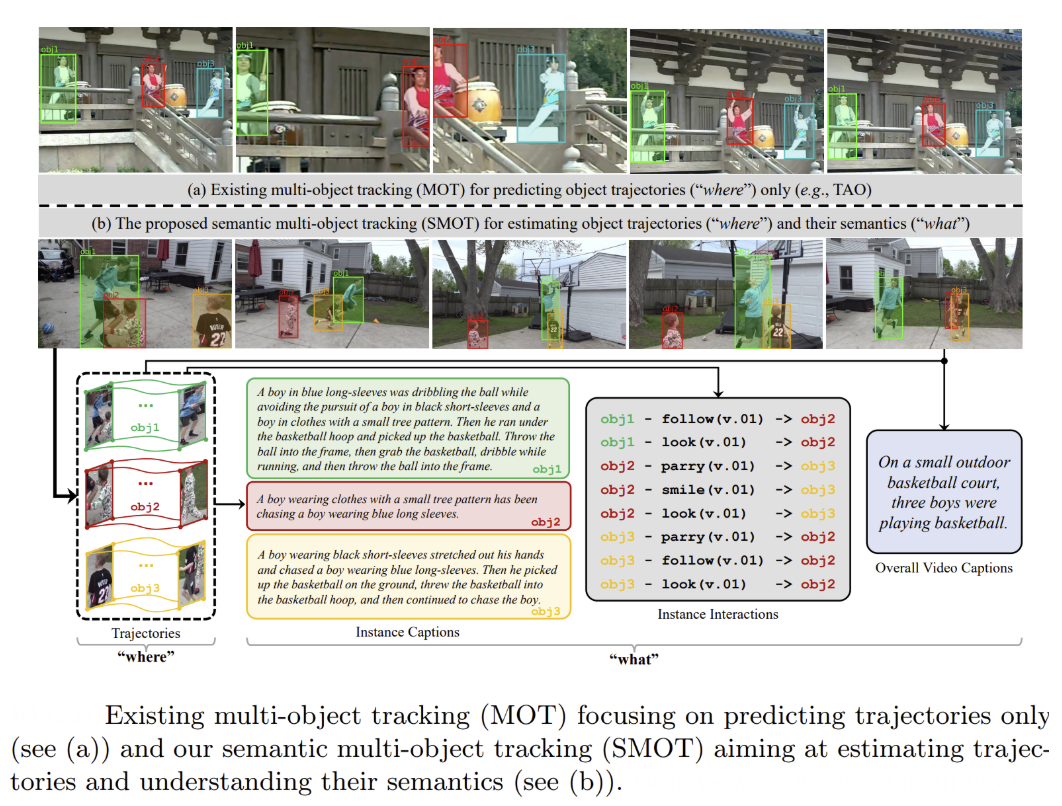
This approach demonstrates how attention mechanisms can capture semantic relationships between objects, with the cross-attention module computing interaction probabilities by attending to relevant features across different object trajectories. The method shows that attention-based fusion works generally better for video-level understanding, achieving superior ROUGE and METEOR scores compared to concatenation-based approaches.
Predictive Trajectory Attention
TrajectoryFormer introduces a predictive trajectory hypothesis generation mechanism that enables robust tracking of objects missed by detectors. Unlike traditional methods that only utilize current frame detection boxes, TrajectoryFormer generates multiple trajectory hypotheses for each tracked object by combining both temporally predicted boxes and current-frame detection boxes, creating a comprehensive set of association candidates that propagate historical trajectory information to the current frame.

The method employs a sophisticated motion prediction network that encodes historical trajectories using a PointNet-like architecture, predicting future states at multiple time steps to generate predicted boxes that can recover objects experiencing short-term detection failures. The predictive attention mechanism operates through a Global-Local Interaction Module that uses transformer-based self-attention to alternately conduct scene-level interactions among all trajectory hypotheses and ID-level interactions among multiple hypotheses of the same object, enabling each hypothesis to gain contextual understanding of neighboring objects and their spatial relationships.
This dual-level attention strategy allows the model to evaluate hypothesis quality by considering both global scene context and local object-specific information, with the system ultimately selecting the highest-confidence hypothesis through learned attention weights that reflect the relative importance of each trajectory candidate.
Decision Transformer for Tracking Failures
The BUSCA framework introduces a Decision Transformer that reframes the challenge of tracking undetected objects as a multi-choice question-answering task, where the "question" is the unmatched track and the "answer choices" are various object proposals generated through sophisticated mechanisms.

The Decision Transformer operates by processing input tokens that include the track's historical observations and a comprehensive proposal set containing three key components: motion-predicted candidates generated through Kalman filtering, contextual proposals from the closest neighboring observations within the track's vicinity, and specialized learned tokens like "Hallucination" for identifying corrupted observations and "Missing" for handling tracks that have genuinely left the scene.
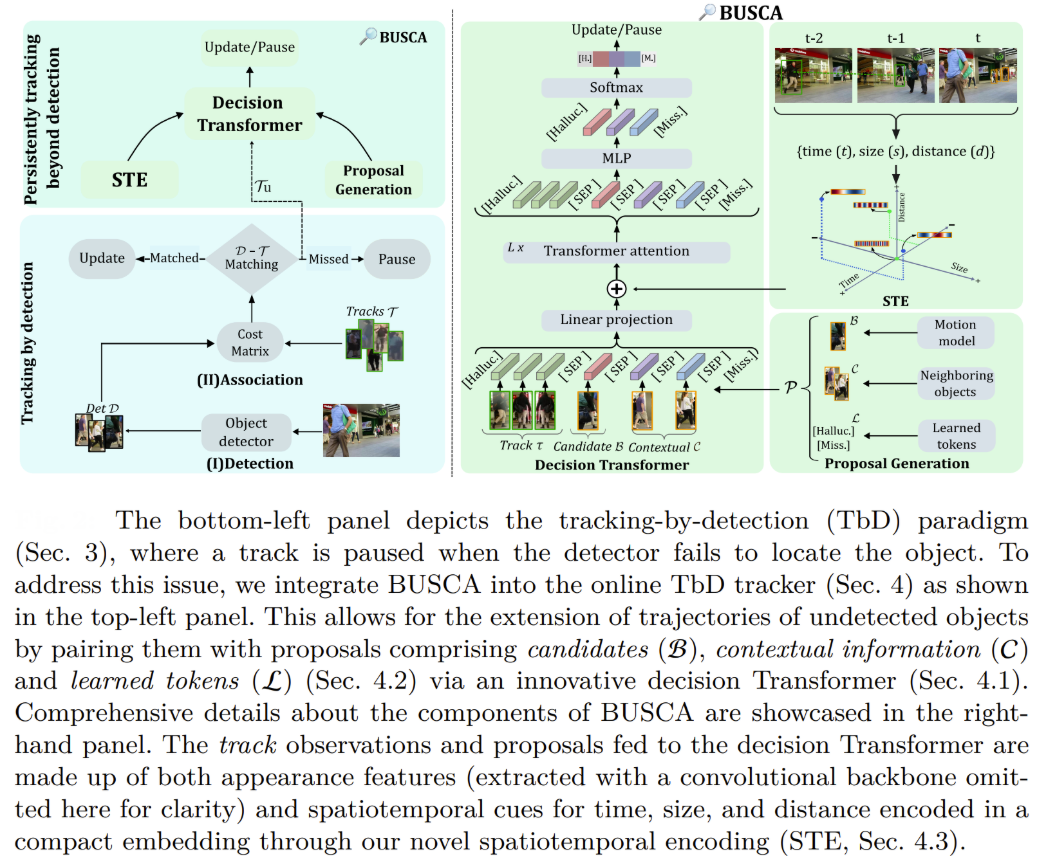
The framework's innovation lies in its spatiotemporal encoder that captures multi-dimensional information including timestamps, bounding box sizes, and 2D coordinate distances through a novel interaction mapping that models relationships relative to an anchor point (the last known observation), enabling the system to learn complex relationships between motion patterns and visual features while maintaining generalization capacity across diverse scenarios. The Decision Transformer employs self-attention mechanisms to refine input tokens by enhancing features most closely related to the target track, followed by a neural network that generates probability scores for each proposal, ultimately selecting the highest-confidence match.

This sophisticated attention-based approach enables BUSCA to make informed decisions about object presence and location even when traditional detection methods fail, achieving consistent performance improvements across multiple state-of-the-art trackers while operating in a fully online manner without requiring future frame information or modifications to past tracking decisions.
Comparison with Tracking-by-Detection Paradigms
The fundamental distinction between end-to-end and tracking-by-detection approaches lies in their architectural philosophy and optimization strategies. While tracking-by-detection methods maintain clear separation between detection and association stages, end-to-end approaches optimize both tasks jointly through unified loss functions. Methods like LAID (Learnable Association by detection and query) represent hybrid approaches that combine the advantages of both paradigms, achieving superior performance while maintaining computational efficiency compared to pure end-to-end methods.

Performance Trade-Offs and Computational Considerations
End-to-end tracking approaches present significant performance trade-offs that must be carefully considered for practical deployment. While these methods achieve superior temporal modeling capabilities and eliminate the need for hand-crafted association rules, they typically require substantially more computational resources and training time compared to tracking-by-detection alternatives.
Recent developments like FastTrackTr and Co-MOT demonstrate that careful architectural design can achieve real-time performance while maintaining competitive accuracy, suggesting that the computational gap between paradigms is narrowing. The choice between end-to-end and tracking-by-detection approaches ultimately depends on specific application requirements and available computational resources.

Technical Challenges
The complexity of Multiple Object Tracking extends far beyond simple detection and association, encompassing fundamental computer vision challenges that have driven decades of research innovation. Understanding these core challenges and their advanced solutions is essential for developing robust MOT systems capable of operating in real-world scenarios.
Core Challenges
Occlusion Handling in Crowded Scenes
Partial and complete occlusion scenarios represent one of the most persistent challenges in MOT, particularly in crowded environments where objects frequently obstruct each other's visibility:
- Partial occlusion: Objects become partially hidden behind other objects, buildings, or environmental elements, leading to incomplete bounding boxes and corrupted appearance features
- Complete occlusion: Objects disappear entirely from view for extended periods, requiring sophisticated prediction mechanisms to maintain tracking continuity
- Inter-object occlusion: Multiple tracked objects occlude each other simultaneously, creating complex disambiguation scenarios
- Environmental occlusion: Static scene elements like pillars, trees, or architectural features create predictable but challenging occlusion patterns
Robust feature representation under occlusion demands sophisticated approaches that can:
- Extract discriminative features from partially visible object regions
- Maintain consistent appearance models despite varying visibility conditions
- Leverage temporal context to compensate for missing visual information
- Employ attention mechanisms to focus on visible object parts while ignoring occluded regions
ID Switching and Trajectory Fragmentation
Causes and mitigation strategies for identity switching stem from fundamental limitations in association algorithms:
- Appearance similarity: Objects with similar visual characteristics confuse association algorithms, leading to incorrect identity assignments
- Rapid motion: Fast-moving objects create large displacement between frames, challenging motion prediction models
- Detection failures: Missed detections force tracking algorithms to make difficult decisions about track termination versus continuation
- Crowded scenes: High object density increases the probability of incorrect associations due to spatial proximity
Long-term tracking consistency requires:
- Robust reid features that maintain discriminative power across extended sequences
- Sophisticated track management systems that can handle temporary disappearances
- Global optimization approaches that can recover from local association errors
- Confidence-based decision making that adapts to varying scene complexity
Similar Appearance Discrimination
Feature learning for distinguishing similar objects addresses the fundamental challenge of maintaining unique identities when objects share visual characteristics:
- Pedestrian tracking: Individuals wearing similar clothing or uniforms create appearance ambiguity
- Vehicle tracking: Cars of the same model, color, or type require subtle discriminative features
- Sports tracking: Players wearing identical team uniforms need specialized identification strategies
- Animal tracking: Species with minimal visual variation demand sophisticated feature extraction
Multi-modal cue integration leverages diverse information sources:
- Appearance features: Deep learning-based visual descriptors from CNN architectures
- Motion patterns: Kinematic information including velocity, acceleration, and trajectory history
- Spatial relationships: Positional context and inter-object distances
- Temporal consistency: Historical appearance and motion patterns for identity verification
Emerging Solutions
Graph Convolutional Networks for Tracklet Relationships
Modeling object interactions and dependencies through graph-based approaches enables sophisticated relationship modeling (example, GCNNMatch):
- Node representation: Individual tracklets serve as graph nodes with rich feature representations
- Edge definition: Spatial, temporal, and appearance similarities define connections between tracklets
- Message passing: Information propagation between connected nodes enables global context integration
- Hierarchical graphs: Multi-level representations capture both local and global object relationships
Temporal graph construction and optimization involves:
- Dynamic graph updates: Continuously evolving graph structures that adapt to scene changes
- Attention-based aggregation: Weighted information combination from neighboring nodes
- Graph neural networks: Learnable graph operations that optimize association decisions
- Global optimization: Joint reasoning across entire graph structures for consistent identity assignment
Siamese Networks for Appearance Similarity
Cross-frame appearance matching leverages twin network architectures for robust similarity computation (examples: SMILEtrack, SiamMOT):
- Shared weight architecture: Identical network branches process different time frames
- Contrastive learning: Training paradigms that maximize similarity for same objects while minimizing it for different objects
- Triplet loss optimization: Anchor-positive-negative training strategies for discriminative embedding learning
- Hard negative mining: Challenging training sample selection for improved generalization
Robust feature learning under appearance variations addresses:
- Illumination changes: Lighting-invariant feature representations
- Viewpoint variations: Multi-angle appearance modeling
- Scale differences: Size-invariant feature extraction
- Temporal consistency: Smoothness constraints for appearance evolution
LSTM-based Motion Prediction
Sequential motion modeling harnesses recurrent neural networks (examples include DRT, Bahari et. al.) for sophisticated trajectory prediction:
- Temporal dependencies: Long-term motion pattern learning through sequential processing
- Hidden state propagation: Memory mechanisms that retain historical motion information
- Bidirectional processing: Forward and backward temporal analysis for improved predictions
- Attention mechanisms: Focus on relevant temporal segments for motion forecasting
Handling non-linear motion patterns requires:
- Complex trajectory modeling: Curved and erratic motion pattern representation
- Multi-modal predictions: Multiple trajectory hypotheses for uncertain scenarios
- Uncertainty quantification: Confidence estimation for motion predictions
- Adaptive prediction horizons: Variable-length forecasting based on motion complexity
Multi-Object Tracking
The landscape of Multiple Object Tracking continues to evolve rapidly, driven by advances in deep learning, transformer architectures, and sophisticated optimization techniques. From the foundational tracking-by-detection paradigms to cutting-edge end-to-end approaches, the field has demonstrated remarkable progress in addressing complex real-world scenarios. The persistent challenges of occlusion handling, identity switching, and appearance discrimination have spurred innovative solutions ranging from graph-based relationship modeling to attention-driven transformer architectures. Recent breakthroughs like ByteTrack's simple yet effective approach, MOTR's end-to-end paradigm, and emerging methods like TrackTrack demonstrate that both heuristic and learning-based approaches continue to push the boundaries of tracking performance.
The future of Multiple Object Tracking lies in the integration of diverse technological advances: quantum computing for optimization, large language models for reasoning-based tracking, and foundation models for universal tracking capabilities. These emerging paradigms promise to address current limitations while opening new possibilities for tracking systems that can operate across diverse domains with unprecedented accuracy and efficiency. For researchers and practitioners entering this dynamic field, the opportunities for innovation remain vast, whether through improving existing paradigms, developing novel architectures, or addressing domain-specific challenges that will enable the next generation of intelligent systems capable of understanding and responding to dynamic environments.
Cite this Post
Use the following entry to cite this post in your research:
Contributing Writer. (Jul 16, 2025). Comprehensive Guide to Multiple Object Tracking. Roboflow Blog: https://blog.roboflow.com/multiple-object-tracking/